Research to Advance AI
Scale Labs advances AI through research. Our research focuses on agents, post-training, reasoning, safety, evaluation, and alignment, and the science of data.
[LEADERBOARDS]
Benchmarks for frontier, agentic, and safety capabilities
[SHOWDOWN]
Model-preference rankings from real-world usage.
[PAPERS]
Research papers and publications covering agents, post-training, reasoning, safety, evaluation, and alignment, and the science of data.
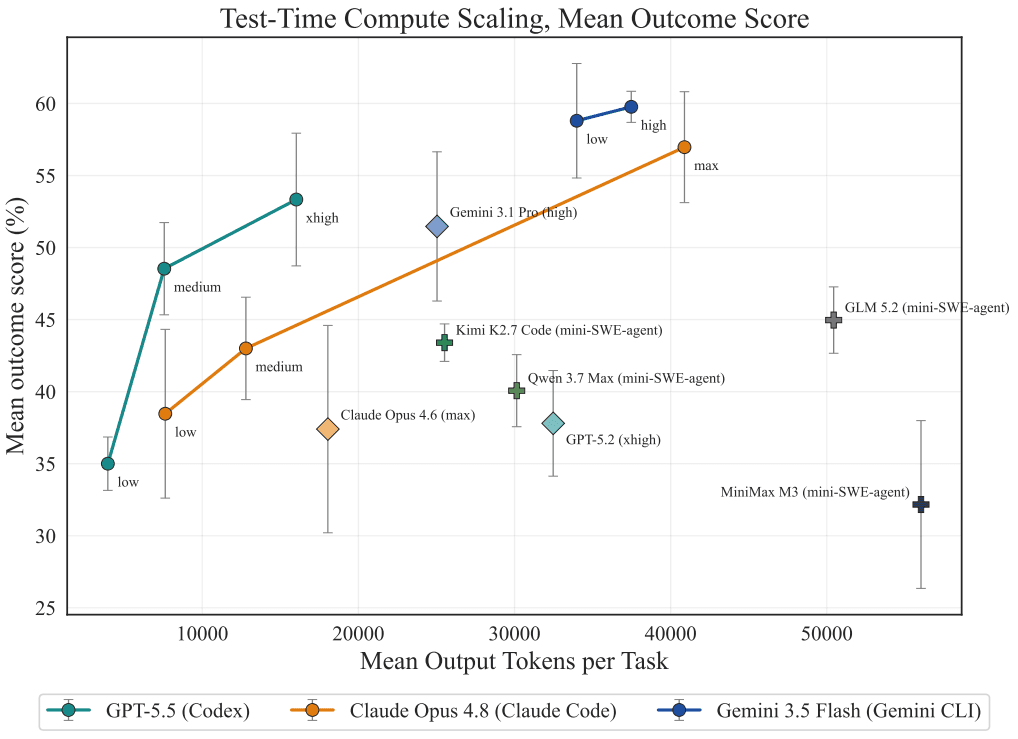
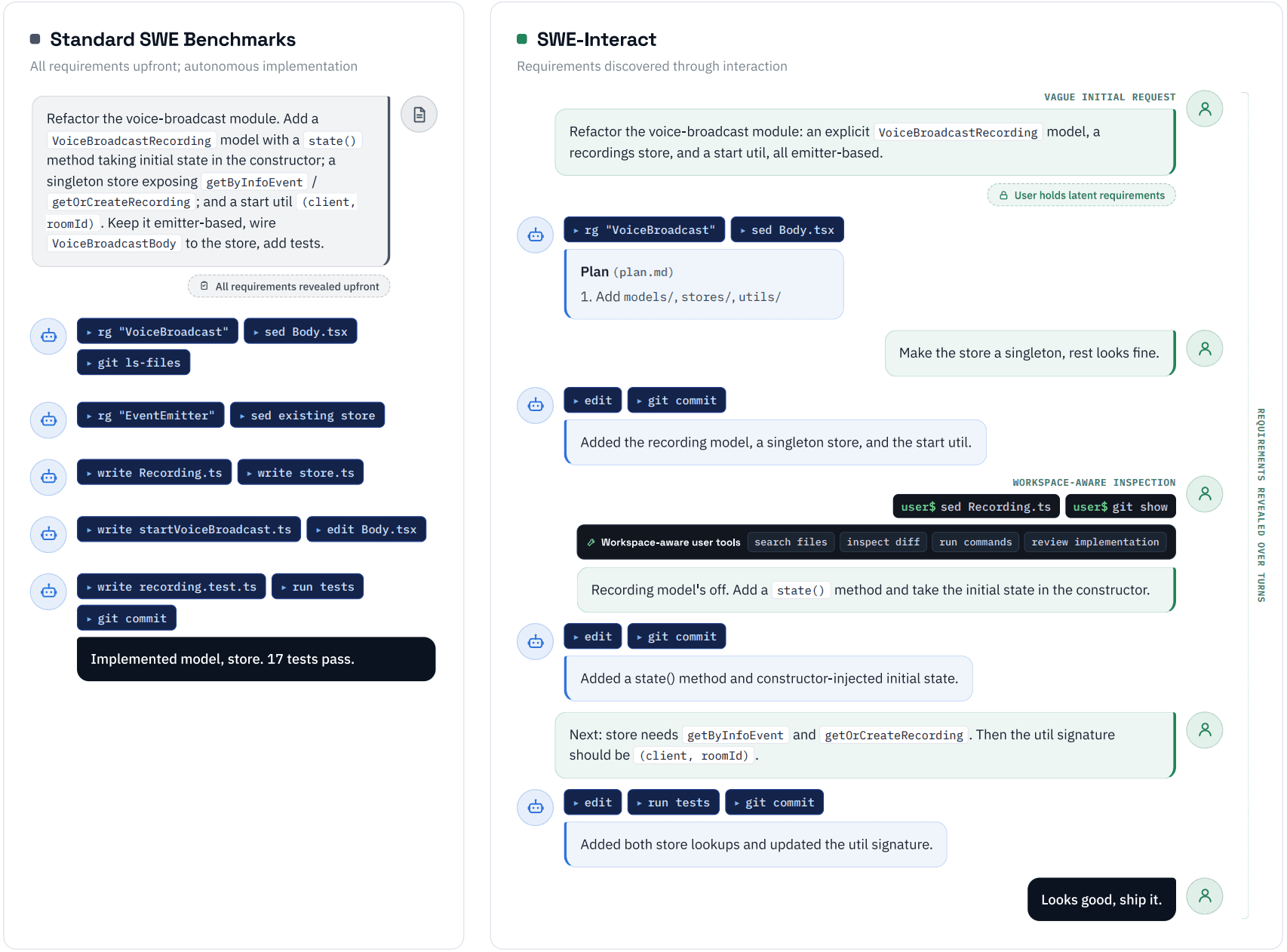
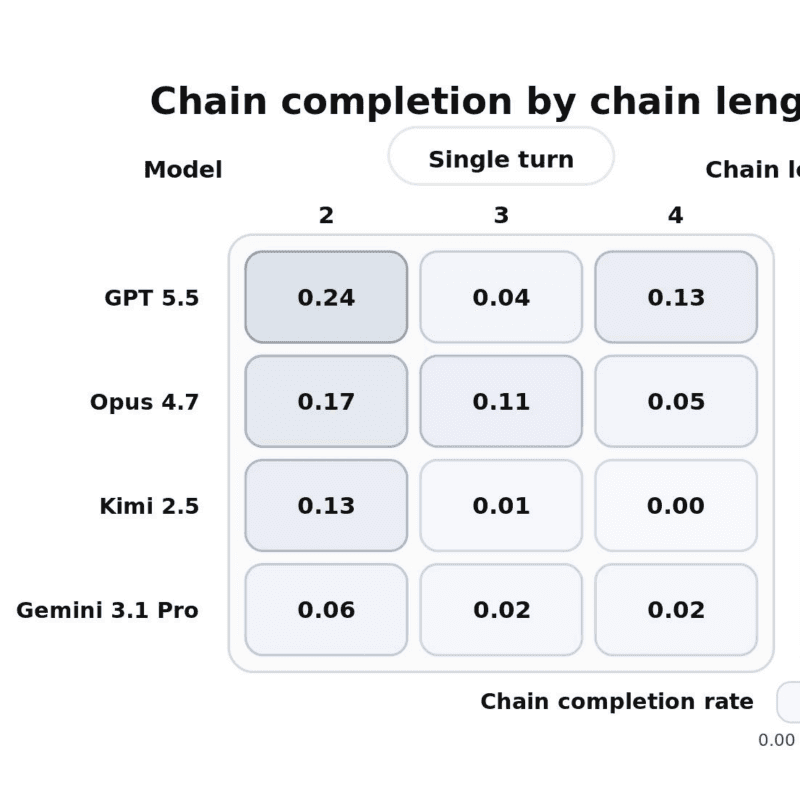
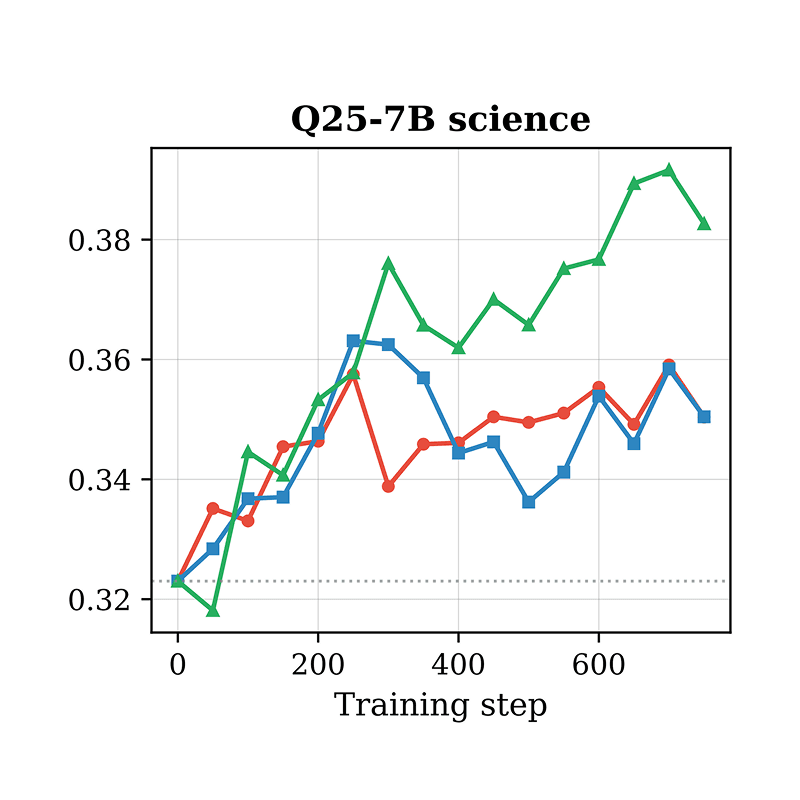
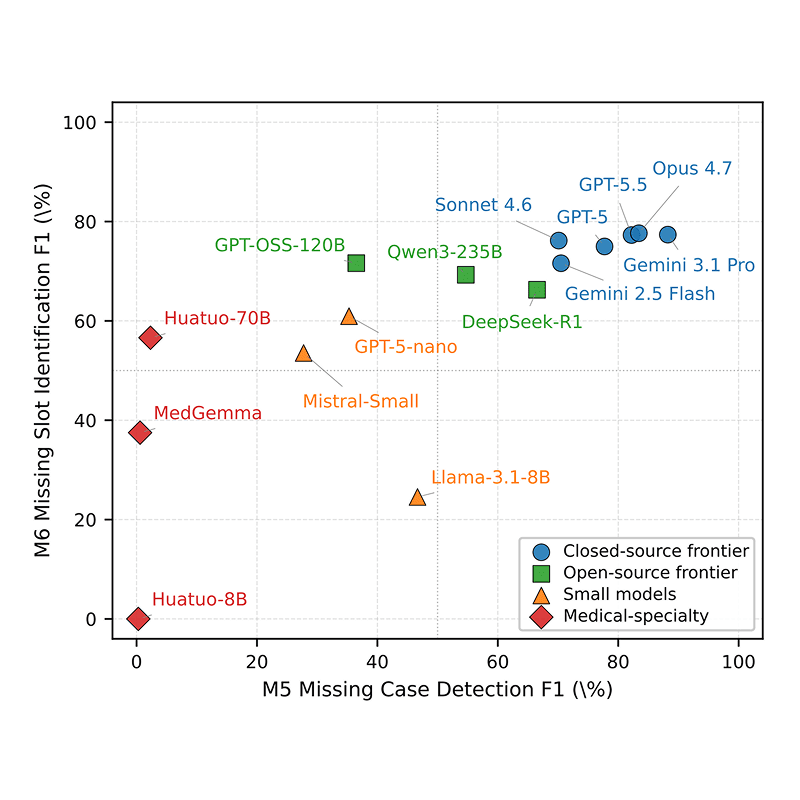
DrugDiscoveryBench: Can Coding Agents Assist Early-Stage Drug Discovery?
[BLOG]
Insights, analysis, and updates from Scale Labs
TERMINAL-BENCH 3.0: Harder Tasks for Better Agents
TERMINAL-BENCH 3.0 is now live with broader coverage, harder tasks, and frontier tracking. Scale contributed the most tasks of any single organization in the launch set.
From Video Review to Measurement: Building Better Robot Data QC
How Scale builds automated quality control for robot training data: why VLMs alone fall short, and why treating QC as measurement works better.
MCP vs. CLI: Does an AI Agent’s Tool Interface Still Matter?
CLI isn't a better default than MCP for AI agents. We ran a controlled 50-task comparison on identical backends across four frontier models. Interface choice matters, but less than you'd think, and the gap closes fast as models improve.
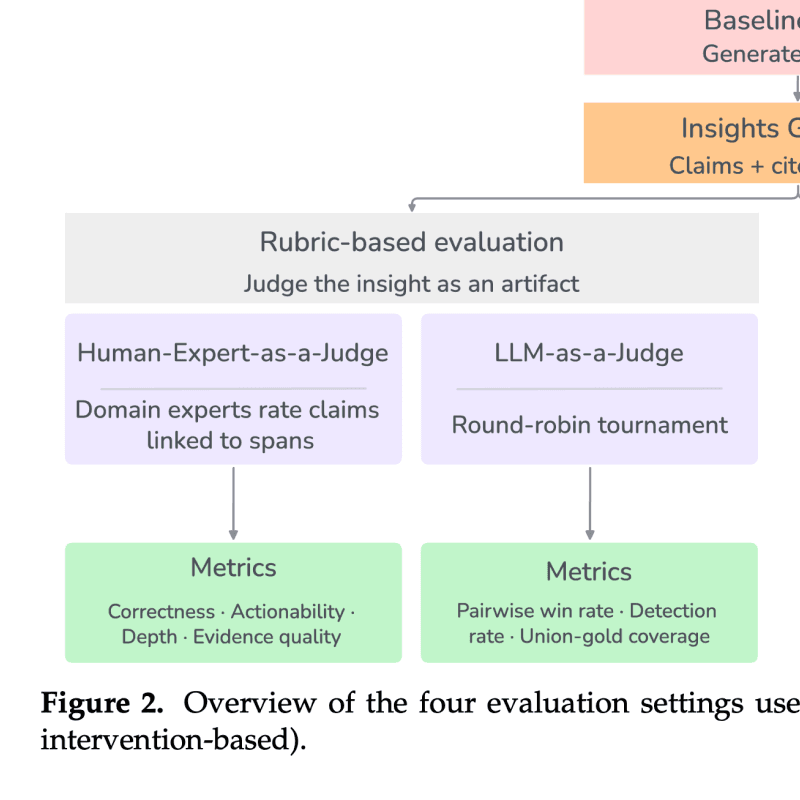
Insights Generator: Automated Failure Mode Analysis for Agents
Insights Generator (IG) analyzes thousands of agent execution traces at once and surfaces the behavioral patterns behind agent failures, with grounded evidence and prevalence estimates for each finding.
View allAll posts